Perceptron
The Perceptron is the first neural network defined algorithmically. The perceptron model is the first model for supervised learning.
Frank Rosenblatt, 1958, 29 years old, builds and demos the Perceptron machine. See New York Times article (New York Times, 1958).
Perceptron architecture
- Has camera that takes photos of 20 x 20-pixel image of cards with colored squares
- 400 pixels converted to 400 binary numbers
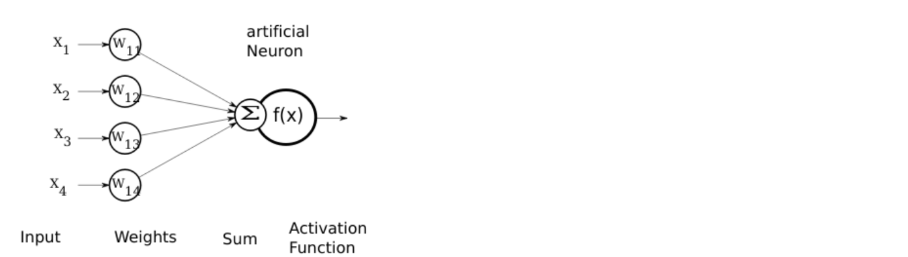 Figure 1 Perceptron’s artificial neuron model. Source: OpenClipArt, 2023.
Figure 1 Perceptron’s artificial neuron model. Source: OpenClipArt, 2023.
- Perceptron classifier model is a single neuron (see Figure 1)
- Inputs are 400 binary numbers (called 400-dimensional input values)
- Parameters are weighted multipliers or weights, which represent the feature vector
- Each of the 400-pixel numbers is weighted by a positive or negative weight
- Unit-step activation function:
- Input: the sum of 400 weighted numbers are added together.
- Output:
- If the sum is positive, the output is 1, meaning the square is on the right of the image card
- Otherwise, the output is -1, meaning the square is on the left of the image card
- Output value is the class label predicted by the activation function
- How are the weights chosen? By a parameter tuning algorithm.
- Initially, the weights are chosen randomly. Thus, the output is non-sensical.
- If the Perceptron is wrong, weights are adjusted
- If too high, weights are turned down
- If too low, weights are turned up.
- The parameter tuning algorithm is called stochastic gradient descent. The algorithm:
- Calculates the difference between
- The target (true class label) and the output (actual class label)
- To determine the gradient (or direction) of the parameter adjustment
- And adjusts the parameters (weights) by lowering (or descending) the error with a value between 0.0 and 1.0, called learning rate.
- Calculates the difference between
- Training data: deck of image cards with a square shape (on the left or on the right)
- After 50 trials, the machine was recognizing accurately the square placements on cards
Rosenblatt’s conjecture
If a perceptron is physically capable to recognize something, then there is a procedure to change the perceptrion’s responses so that it eventually would carry out the task.
Rosenblatt guessed the perceptron convergence theorem, which was proved for single-layer neural nets. Perceptron algorithm is used for supervised learning of binary classification of patterns that are linearly separable.
Less than 10 years later, in 1969, Marvin Minsky and Seymour Papert wrote The Perceptrons book. In the book, they show with mathematical proof that there are simple patterns that the perceptron will never be able to recognize.
Minsky and Papert conjecture
In the last chapter of their book, Minsky and Papert make the conjecture that the limitations they had discovered for Rosenblatt’s perceptron would also hold true for its variants — more specifically, multi-layer neural networks.
Multi-layer neural networks
History has shown that Minksy and Papert were wrong.
The multi-layer neural networks convergence theorem demonstrates that neural networks are computationally more powerful than the perceptron.
To recognize more complex categories (e.g., non-binary), the network needs multiple layers
- Representation of raw data is the first layer
- Later layers operate on earlier layers’ representation.
- Questions
- How to tune the parameters of the earlier layers?
- How to determine the gradient update?
Answer: back propagation algorithm.
In 1989, 30 years after Minsky and Papert stated their conjecture
- Rumelhart Hinton, and Williams proposed the back propagation in their paper “Learning internal representations by error propagation”.
- The back propagation algorithm trains multi-layer perceptrons.
- Idea
- Chain rule from calculus requires differentiable neurons, not “all or nothing” neurons.
References
Bargen, Danilo. 2023. Programming a Perceptron in Python. blog.dbrgn.ch. https://blog.dbrgn.ch/2013/3/26/perceptrons-in-python/
Lefkowitz, Melanie. 2019. Professor’s perceptron paved the way for AI – 60 years too soon. https://news.cornell.edu/stories/2019/09/professors-perceptron-paved-way-ai-60-years-too-soon
Open ClipArt. 2020. Artificial Neuron. Free SVG. https://freesvg.org/artificial-neuron.
Wallner, Emil. 2017. The History of Deep Learning Explored with 6 Code Snippets. freeCodeCamp.org. https://www.freecodecamp.org/news/the-history-of-deep-learning-explored-through-6-code-snippets-d0a0e8545202/
Optional References
Haykin, Simon. 2008. Neural Networks and Learning Machines. Prentice Hall, 3rd edition.
New York Times. 1958. New Navy Device Learns by Doing.
Rosenblatt, Frank. 1960. Perceptron Simulation Experiments. Proceedings of the IRE, vol. 48, no. 3, pp. 301-309, March 1960, doi: 10.1109/JRPROC.1960.287598.
Wallner, Emil. 2023. Deep Learning from Scratch. GitHub. https://github.com/emilwallner/Deep-Learning-From-Scratch/blob/master/Perceptron.ipynb